


I’m fairly certain that I was not the only person in the world who thought to himself, “Did they just yoink the entire Internet and bundle it together into a glorified copy and paste machine?” upon the release of ChatGPT.
And even though there are some concerns about the type of data that was used to train OpenAI’s latest model, it seems that the overall stance of OpenAI and other companies working on similar projects is that it is fair use. Whether or not that is going to hold up in the long run, remains to be seen.
After Google published an announcement saying they’re interested in exploring alternatives to robots.txt to provide broader control over AI-related content issues, I was curious to see what other search engines are doing in regard to AI, both for dealing with AI-generated content but also handling data.
Personally, I’m not a big fan of these conglomerates ingesting other people’s work and then reselling it, which also leads me to the story I’m going to talk about today.
An update from Brave has been added at the bottom of the article! ↗
I have published a new article which is an update and shows how Brave can scrape licensed content, read it here:
https://stackdiary.com/an-update-on-brave-selling-copyrighted-data/
Brave gives you “rights” to use data for AI inference/training
As you may have noticed, I used the word copyrighted for the title of this story. And it’s not without reason. I think this story could have been fairly decent even without the copyright part, so before we get to the nitty gritty stuff – I can 100% confirm that Brave lets you ingest copyrighted material through their Brave Search API.

Rather than talking about it too much, I thought the logical thing to do would be to sign up for the API and see what kind of data we can find. For its Data for AI product, Brave offers something called “Extra alternate snippets”, which are very similar to what we know as Google’s Featured Snippets.
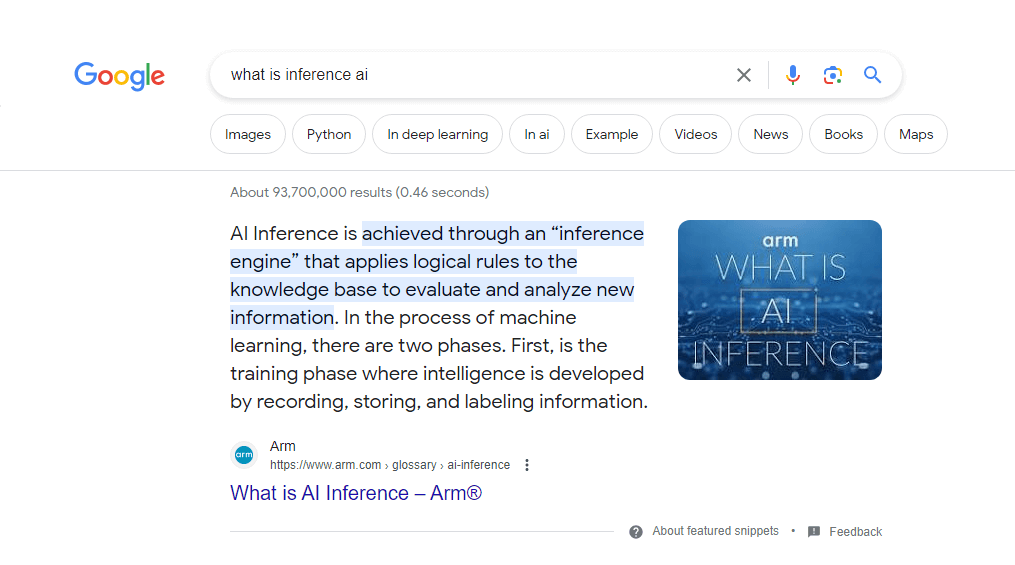
Google’s featured snippets tend to be rather short (no more than 50 words), which from a copyright point of view can be classified as fair use.
So, after doing a few queries with Brave’s Search API – I was rather surprised to see how generous their snippets are; in this example below – the “extra_snippets” range from 150 to 260 words.
Here is the cleaned-up JSON response from the API; this particular response was from a query “Brave Search”, and the “extra_snippets” are extracted from this Wikipedia page. Mind you; this is for a single query from a single site, not taking into account the other (mentioned below) search features that Brave provides through its Data for AI API.
"extra_snippets":[
"Brave Search is a search engine developed by Brave Software, Inc. and released in Beta in March 2021, following the acquisition of Tailcat, a privacy-focused search engine from Cliqz. Brave Search aims to use its independent index to generate search results. However, the user can allow the Brave browser to anonymously check Google for the same query.",
"In October 2021, Brave Search was made the default search engine for Brave browser users in the United States, Canada, United Kingdom (replacing Google Search), France (replacing Qwant) and Germany (replacing DuckDuckGo). In June 2022, Brave Search ended its beta stage and was fully released.",
"In June 2022, Brave Search ended its beta stage and was fully released. In addition to the launch, the new Goggles feature was added, allowing users to apply their own rules and filters to search queries. Brave search has various features designed to enhance users' searching experience:",
"Brave search has various features designed to enhance users' searching experience: Brave Search uses its own web index. As of May 2022, it covered over 10 billion pages and was used to serve 92% of search results without relying on any third-parties, with the remainder being retrieved server-side from the Bing API or (on an opt-in basis) client-side from Google.",
"Brave Search is a search engine developed by Brave Software, Inc., which is set as the default search engine for Brave web browser users in certain countries. Brave Search is a search engine developed by Brave Software, Inc. and released in Beta in March 2021, following the acquisition of Tailcat, ..."
]I know for a fact that Wikipedia operates under a CC BY-SA 4.0 license, which explicitly states that if you’re going to use the data, you must give attribution. As far as search engines go, they can get away with it because linking back to a Wikipedia article on the same page as the search results is considered attribution.
One might argue that even 260 words are not useful enough for any real impact, but I’m not sure that is the case (besides the whole copyright thing) because not only can you manipulate these results and fine-tune the output based on domains, type, date, and other metrics – Brave also offer additional API features for paid customers, such as:
- Schema-enriched Web results
- Infobox
- FAQ
- Discussions
- Locations
All of which can be used to extract very specific information, and then be used to fine-tune LLMs because Brave acts as a middleman.
Brave doesn’t disclose its own robot crawler
I get anywhere from 30 to 50 visitors a day from Brave’s search engine. But, if I go through my access.log files, I won’t find any indication that a Brave crawler is regularly crawling my content.
They do have something called the Web Discovery Project, but from what I gather – it’s an opt-in feature, so you must explicitly agree to it before you partake in the initiative.
The Web Discovery Project is a privacy-preserving way for you to contribute to the growth and independence of Brave Search. If you opt in, you’ll contribute some anonymous data about searches and web page visits made within the Brave Browser (including pages arrived at via some, but not all, other search engines). This data helps build the Brave Search independent index, and ensure we show results relevant to your search queries. By “data” we mean search queries, search result clicks, the URLs of pages visited in the browser, time spent on those pages, and some metadata about the pages themselves.
After some more digging, I was able to find a Reddit comment from Jonathan Sampson, Senior Developer Relations at Brave, who said the following:
We do indeed have our own crawler, actively building our own index. Presently the index consists of over 8 billion pages, with more than 40M crawled each day. The crawler, which does not contain a unique user-agent string, respects robots.txt.
They don’t mention their crawler anywhere in their docs, either. So, if you wanted to block Brave from crawling and indexing and ultimately selling your content to third parties, your only option for the time being would be to block all crawlers, which is how Brave would be able to “respect robots.txt”.
And don’t get me wrong, I love Brave, and I’ve given them credit where it’s due; it’s also my understanding that the Brave Search API feature is new as a whole (released in May 2023), so perhaps it wasn’t or hasn’t been thought through completely.
An update from Brave
As I said, I would update this article once Brave replies to my email. They did so last night, but at an hour that was not convenient for me (I did propose that they go and reply in this Hacker News thread, which was an active discussion at the time of the email), and they tried to push me to include the reply here right away, but I chose not to because I simply wouldn’t have had the time to process it.
I have done a follow-up, but because it’s Sunday, I am not exactly expecting another response.
Here is the initial email from Josep M. Pujol (Chief of Search at Brave):
This initial email doesn’t do a great job of answering things like:
- How does Brave handle various licenses? Is there an automated system to check a site’s license and then skip things like showing 260-word blurbs of word-for-word copy/pasted content? For example, if I was to add a CC BY-NC-ND license to this site, how would Brave handle it? This particular license clearly states that the content cannot be used for commercial purposes.
- Brave’s reasoning for not disclosing their Search Crawler is that it is for “practical reasons” as they don’t have the resources to contact all domain owners who “block” or “discriminate” against them. That doesn’t make any sense whatsoever and feels like a red flag of bypassing websites explicitly blocking their crawler. Unless, of course, you choose to block Google’s crawler, and then that will make Brave happy.
And as far as calling my article an assumption goes, it quite literally says on their Brave Search API page that you get “Rights to use data for AI inference”. That same page does not explain licenses, as it stands – their API is a pipeline that you can use to gather fine-grained data.
Brave doesn’t care if it’s licensed one way or another; apparently, they can monetize other people’s licensed content because they’re a search engine.
The rights are to the output of the API request, which is a set of results to a query sent by the API user. Brave Search has the right to monetize and put terms of service on the output of its search-engine. The “content of web page” is always an excerpt that depends on the user’s query, always with attribution to the URI of the content. This is a standard and expected feature of all search engines.
Josep M. Pujol, Chief of Search at Brave
I’m genuinely curious how “content” and “output of the API request” are two different things, particularly when I already showcased that they give you word-for-word “extra snippets”.

I’m not having very high expectations for the follow-up email I sent asking about the concerns above, but I’ll make sure to do another update when it does happen.