


The AI-based “knowledge base” startup Perplexity is making the rounds in mainstream media about plagiarizing an original-reporting Forbes story.
Forbe’s reporters are upset that Perplexity took their exclusive story and copied parts of it verbatim while giving Forbes little to no attribution. In fact, in the initial version of the story – Eric Schmidt’s AI Combat Drones – Perplexity didn’t even attribute the reporting to Forbes within the content body itself. It has since been rectified by adding “as reported by Forbes” inside the generated page.
Although that change has been made, a few days after Forbes put out its public complaint, Perplexity has since demoted Forbes as one of the leading sources on the story:
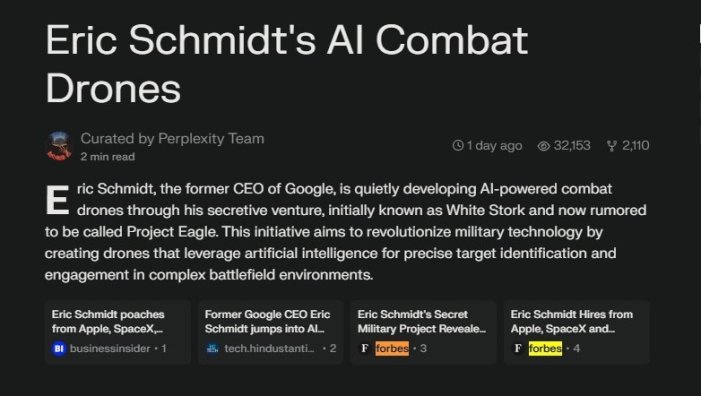
Both Business Insider and Hindustan Times, attributed as first links, are reporting on the Forbes coverage.
Perplexity’s CEO, Aravind Srinivas, took to Twitter to say that their product has some “rough edges” and that he agrees that “it should be a lot easier to find the contributing sources and highlight them more prominently”.
So, let’s break this down, and maybe we can decipher the fact that “rough edges” aren’t exactly a valid argument when your entire product is based on plagiarism, not only for written content and reporting but also for images.
Perplexity launches Pages, an automated LLM content aggregator
On May 30, 2024, Perplexity announced that it had launched Pages, a new feature that aggregates content from all over the web and gives that content a separate page, which acts as an article on the subject.
In their own words, “Perplexity Pages helps users easily turn research into visually appealing, well-structured articles, reports, or guides. It offers customizable tone, adaptable structure, and integrated visuals, making it ideal for educators, researchers, and hobbyists to share their knowledge effectively”.
You can see what that looks like here: Musk Drops Lawsuit Against OpenAI.

Another thing you’ll notice about these Pages is that apart from plagiarising text, they also steal images. In every case, they do so without giving any attribution. In the same story linked above, Perplexity has taken an image from a Wall Street Journal story. Still, WSJ itself is not mentioned in the generated page, nor is the image attributed. This means that Perplexity uses some other photo library (Google Images, most likely) to fetch relevant photos for their Pages.
In fact, not a single image on the entire Perplexity platform is attributed to license information. It merely mentions the site’s name in the form of “site.com,” and clicking on the image simply opens a gallery of all the images on the page.
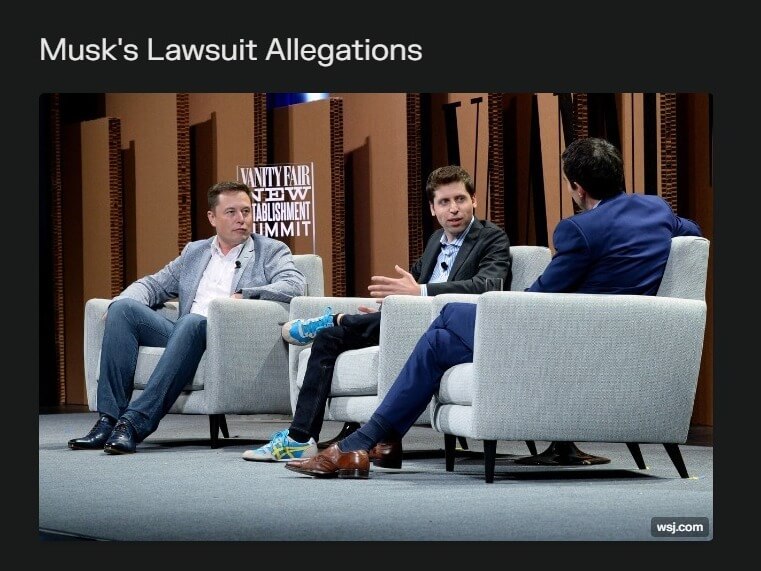

The “attribution” that Perplexity has added is in the form of a hyperlink in the top-right corner of the gallery. You would literally never notice that link there unless you were specifically looking for it. That hyperlink is not a valid argument against a photo’s license because that’s not how it works.
The WSJ story where this image was taken from – How the Bromance Between Elon Musk and Sam Altman Turned Toxic – attributes the image as follows:
Elon Musk, left, and Sam Altman, center, in 2015, the year the two men co-founded OpenAI as a nonprofit research lab. PHOTO: MICHAEL KOVAC/GETTY IMAGES FOR VANITY FAIR
Getty Images is a stock photo agency that licenses images for a fee. Using their photos without permission constitutes copyright infringement. Simply mentioning the site name does not provide legal protection or satisfy licensing requirements. Getty Images does not take it lightly when their photos are being infringed upon, and they most definitely have the resources to take legal action.
Big publishers have deals with Getty and other photo agencies that allow these publishers to license images in various ways. Perplexity has no such deal with Getty. This attitude towards taking external images extends to each and every one of their auto-generated pages. There’s literally zero concern for who made or produced the image.
In their Terms of Service (section 6.5), they say that if you “believe” that your work has been infringed upon, you can send a notice about it to them. Well, there isn’t anything to believe in—it is a simple fact.
How is this different from a journalist writing on someone else’s story?
Let’s put aside the blatant image plagiarism and focus solely on text. When someone breaks a story, many other journalists and writers will jump on that story and write about it. That story will have one singular source, and everyone else who writes about it afterward will attribute the initial source.
This is a standard journalistic practice. Even when a journalist has more to add or something to counter, they will still provide the original source’s attribution because it gives context to their writing.
Perplexity does this by including the bare minimum attribution in the form of a source links button. However, the real problem is that it pools together multiple sources at the same time and then presents its own page as a complete story. At no point in reading any of the Pages generated by Perplexity will you feel like an original narrative is happening – it has simply automatically aggregated hours of other people’s work and presented it as the one true source.
Here is an example result from Google when searching for the phrase “Marianne Bachmeier,” which, according to AdWords keyword data, has roughly 40,000 monthly searches. Google has given Perplexity a prime-time spot for this – literally the best possible position you can dream of as a content producer.
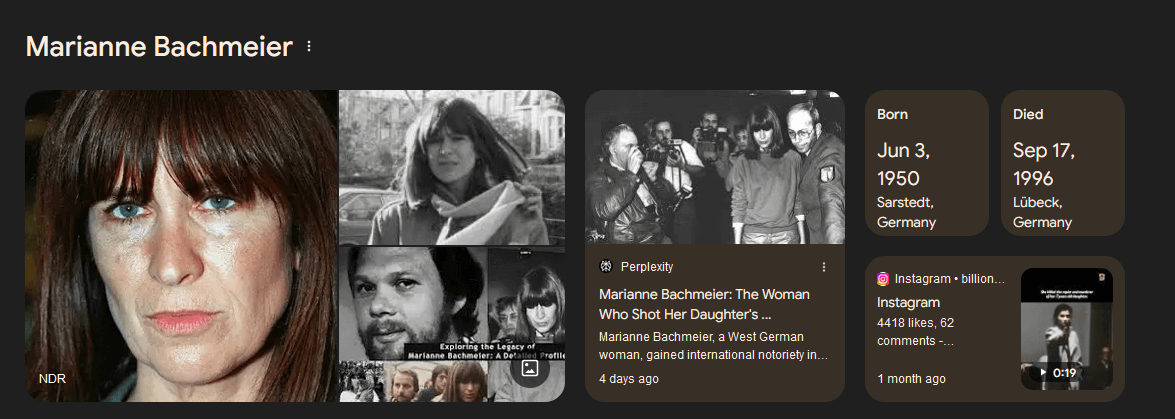
The Perplexity page in question is Marianne Bachmeier: The Woman Who Shot Her Daughter’s Killer in Court. This page says that it has been “Curated by eliot_at_perplexity.” But if you sit down to read it for yourself, it takes a minute to realize that it is yet another auto-generated AI slop.
Perplexity concludes the story in five different ways.
It does this because these stories are generated using specific prompts instructed to report on sources in a specific way. For each different sub-heading, you always get a similarly worded conclusion. There is no cohesive narrative but a repetition of the same facts as told by actual investigative reporters and those with direct experience on the subject matter.
As shown earlier, the images used in this story have no attribution either. In fact, Perplexity takes the images and hotlinks them:
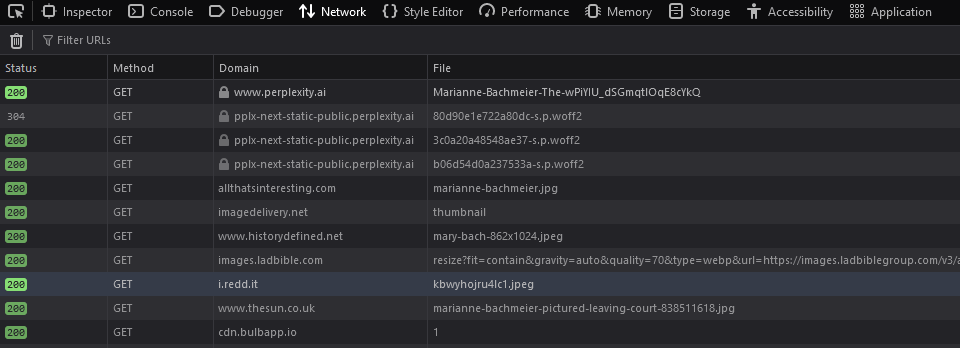
This is quite literally despicable behavior.
You work, we profit.
In January 2024, Perplexity announced it had raised a cool $73 million from investors like Jeff Bezos, NVIDIA, and others. I wonder how Bezos feels about having the Washington Post’s paywalled stories gobbled up by Perplexity. After all, he purchased the magazine over a decade ago.
I mean, I get it. I even understand people who use Perplexity for its main purpose – to aggregate several answers from multiple sites at once. Instead of being shown ten blue links on Google, you get shown five direct answers on Perplexity.
But this plagiarism thing, the way that it is implemented now needs to stop.
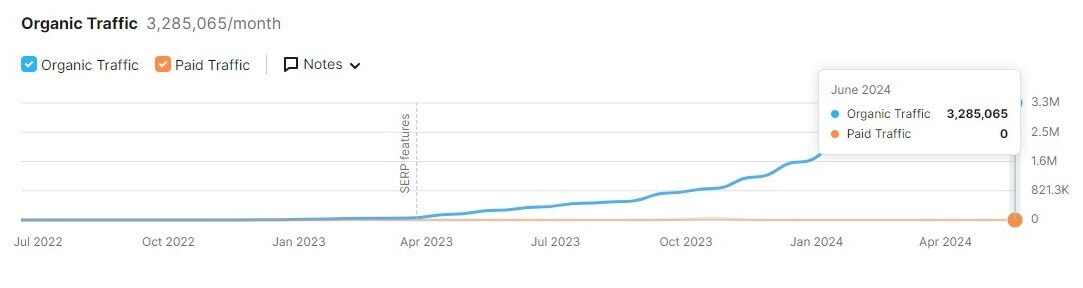
According to Semrush, Perplexity has grown to roughly 3.2M monthly visitors from Google, but the number is likely much higher.
Semrush also shows us that after introducing the Pages feature, Perplexity doubled the number of keywords it shows up for in Google:
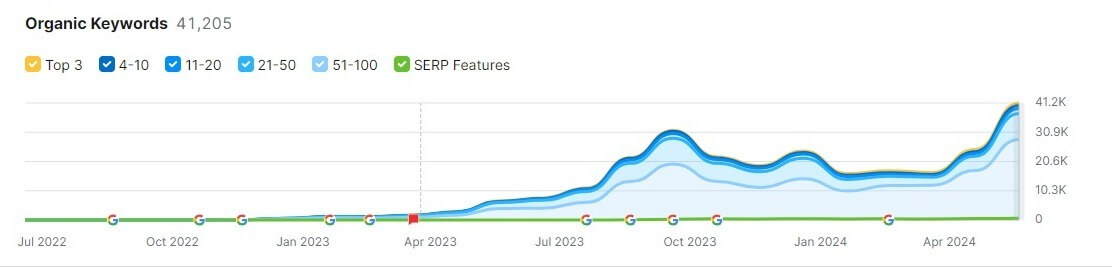
And it did so through nothing but plagiarism. It took other people’s work—their time, resources, and creativity—and slapped a prompt at it to tell an LLM, “Rewrite this as though you are the original source of this story.”
BBC wrote a report in May on how Google has changed its algorithms and how that has caused many smaller publishers to lose their livelihoods, even though their content is original and written in the first person. An algorithm can somehow decide that a publisher is not helpful, but it can’t decide about blatant plagiarism. In fact, it rewards it.
Those 3.2M users that Perplexity enjoys from Google Search could have easily gone to those same creators, be they small publishers or editorial journalists who actually have to go out into the world and get the facts on what they report.
Make no mistake that Perplexity does no original reporting of its own. It’s an aggregator and an automated one at that. It steals not only your words but also photos, and come to think of it – it might as well be stealing whatever little willpower and integrity you have left in this age of AI.