


Reddit, one of the internet’s most popular social platforms, has updated its robots.txt file to block all web crawlers. This change builds on the company’s ongoing efforts to protect user privacy and control the misuse of its content. Announced in a blog post on May 9, 2024, Reddit introduced its new Public Content Policy to clarify its stance regarding access to public content while emphasizing user protections.
This new policy aims to address the increase in unauthorized data collection and misuse on its platform. Reddit stated, “We need to do more to restrict access to Reddit public content at scale to trusted actors who have agreed to abide by our policies.”
Reddit has not explicitly shared who its partners are. We asked Reddit point blank if they have some special deal with Google because, for now, Google keeps indexing Reddit pages, whereas other search engines no longer do so.
A spokesperson told us that, “In line with what we shared last week, we’ve ramped up blocking third parties – like bots and crawlers – that do not abide by our Public Content Policy and have an agreement in place with us.” – that blog post mentions that the Internet Archive wouldn’t be affected, but it makes no mention of any search engines.
We followed up and were told, “We can’t share any more information other than what we shared in our partnership announcement with Google earlier this year.”
That announcement is about a $60M firehose deal with Reddit to fetch data from its API. However, this deal is only specific to Reddit’s Data API and is intended for AI training purposes and use in features like AI Overviews.
We have also asked Google the same question about whether or not they plan to respect this robots.txt change—we have not yet received a response.
The robots.txt file is a way for websites to handle interaction with web crawlers, which are automated programs used by search engines and other services to index and analyze website content. By modifying this file, websites can control which parts of their site can be accessed by these crawlers. Reddit’s previous robots.txt, dated July 3rd, displayed a regular-looking ruleset, allowing broad access with few restrictions.
The new robots.txt file, however, implements a blanket disallowance for all user-agents:
User-agent: *
Disallow: /This means that no web crawler, irrespective of its purpose or affiliation, can access and index Reddit’s pages. This is at each crawlers own discretion, but typically – search engines and various archive/indexing services will respect these rules.
As for the updated robots.txt file taking effect, we checked and verified that Bing, DuckDuckGo, Yandex, Yahoo, and other search engines have not indexed any pages from Reddit in the past 24 hours:
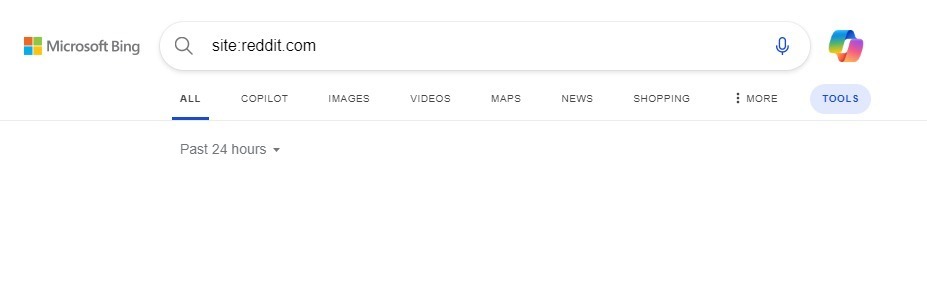
Google, on the other hand, still keeps doing it.
We know that Google is using an older version of the robots.txt file:
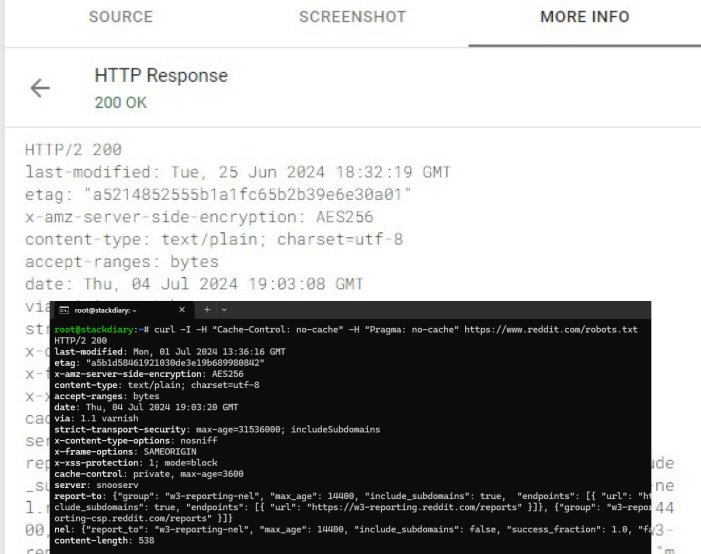
You can perform the same test by going to the Rich Results Test page and entering the address for Reddit’s robots.txt file; from there, you need to click “View Tested Page” from the sidebar you need to select “More info,” and then click on “HTTP Response”. This will show that Google uses a robots.txt file that was last modified on June 25.
Using the Tame the Bots simulator (to fetch the page as Googlebot), it says that the request is “Blocked by robots.txt.”
Some people on social media have said that Google is getting the IP range treatment, meaning that Reddit is letting Google’s crawler use the old version based on its IP ranges; this does not entirely convince us (yet).
Here is a list of popular search engines and their current status with Reddit:
| Search engine | Indexing new pages from Reddit? |
|---|---|
| ✅ | |
| Bing | ❌ |
| DuckDuckGo | ❌ |
| Yandex | ❌ |
| Yahoo! | ❌ |
| Brave Search | ❌ |
| Mojeek | ❌ |
| Baidu | ❌ |
Reddit’s reasoning behind the block
The updated robots.txt file maintains the message about believing in an open internet but underscores a stricter stance against the misuse of public content. By blocking all web crawlers, Reddit aims to control the extensive use of its data, which often fuels various applications ranging from academic research to commercial data mining.
# Welcome to Reddit's robots.txt
# Reddit believes in an open internet, but not the misuse of public content.
# See https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-Policy Reddit's Public Content Policy for access and use restrictions to Reddit content.
# See https://www.reddit.com/r/reddit4researchers/ for details on how Reddit continues to support research and non-commercial use.
# policy: https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-PolicyThis significant change has multiple implications. On one hand, it could limit the ability of researchers and developers to access Reddit data for legitimate, non-commercial purposes. Reddit acknowledges this potential drawback and directs researchers to a specific subreddit for support:
“See https://www.reddit.com/r/reddit4researchers/ for details on how Reddit continues to support research and non-commercial use.”
On the other hand, this move can be seen as a protective measure against the rampant exploitation of its vast user-generated content for purposes such as AI training. In 2023, Reddit’s CEO, Steve Huffman, used the LLM argument to (in part) justify changing Reddit’s API policy, which was a massive scandal.
When asked, “Were these API changes already in the pipeline prior to ChatGPT or is this really a knee-jerk response”, Huffman replied by saying,
Yes and no. Two things happened at the same time: the LLM explosion put all Reddit data use at the forefront, and our continuing efforts to reign in costs to make Reddit self-sustaining put a spotlight on the tens of millions of dollars it costs us annually to support the 3P apps.
Of course, this is a bit of a pipe dream on Reddit’s part because those who want to get the data and use it for such purposes, even if it means illegally, would likely do so despite what restrictions Reddit intends to impose.