


Alibaba Group’s Institute for Intelligent Computing has unveiled a method to bring still images to life. Their approach, named “Animate Anyone” transforms characters from photographs into animated videos, setting new standards in digital animation.
The team, led by Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo, has developed a way to animate any character in a photo, creating high-quality, clear, and stable video results. This is particularly notable for its ability to maintain the character’s appearance details consistently throughout the animation.

At the core of this technology are advanced computer models known as diffusion models, which have recently become the go-to method for generating digital images and videos. The Alibaba team has harnessed these models to tackle the challenge of animating characters from still images, a task that has traditionally been fraught with issues like distortion and inconsistency.
Their method stands out in its ability to handle detailed features of the characters. This is achieved through a special component called ReferenceNet, which captures and integrates the intricate appearance details from the reference image into the animation process. Another key element is the Pose Guider, which directs the character’s movements in the video, ensuring they are realistic and fluid.
The team’s approach can animate various characters, including human figures, cartoons, and humanoid figures. The resulting videos are visually stunning and exhibit remarkable temporal consistency, meaning the animation flows smoothly over time without any jarring transitions or flickers.
This technology has vast potential applications, from online retail to entertainment and artistic creation. It represents a significant step forward in the field of character animation, opening up new possibilities for creators and developers in various industries.
In testing their method, the Alibaba researchers have focused on two specific areas: fashion video synthesis and human dance generation. In fashion video synthesis, their technology turned static fashion photographs into realistic, animated videos. The results were impressive, particularly in maintaining the fine details of clothing, which is crucial in the fashion industry.
The team used their method to animate single human figures in dance scenarios for the human dance generation. The results again stood out for their realism and fluidity, effectively capturing the complex movements of dance.
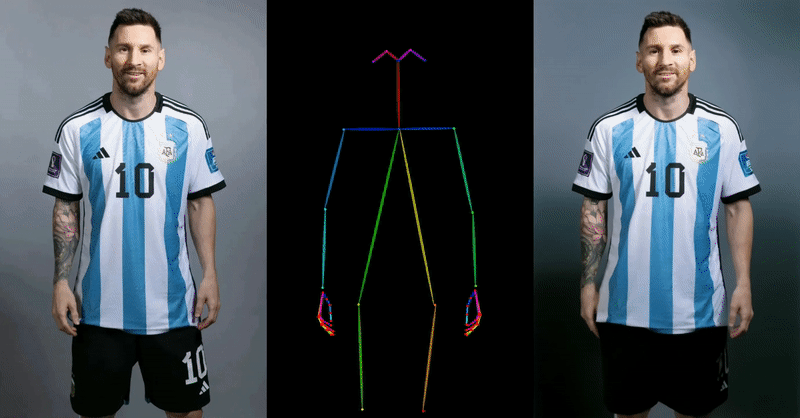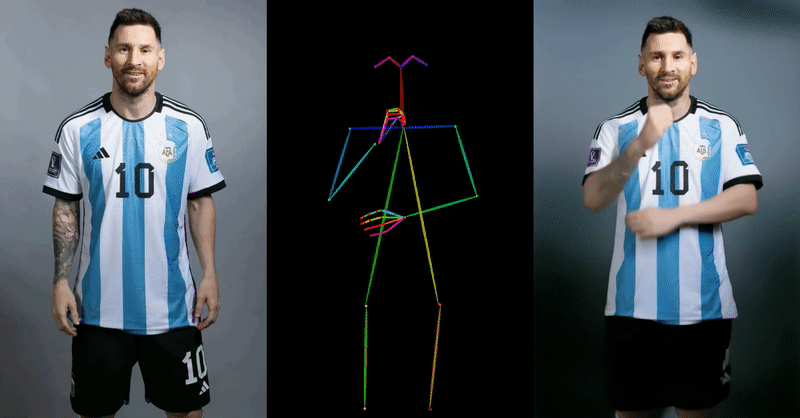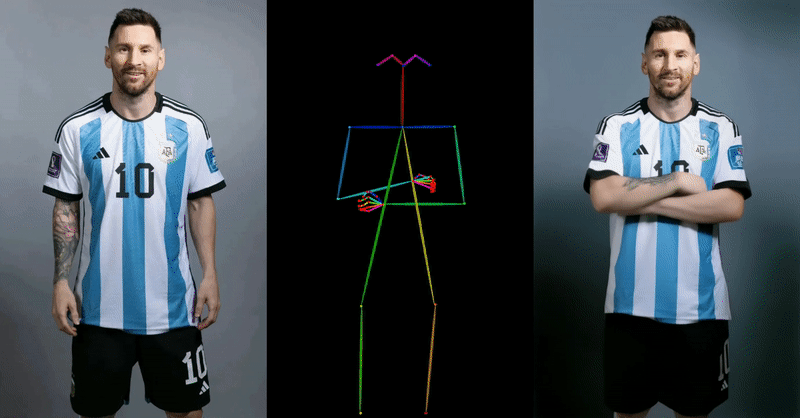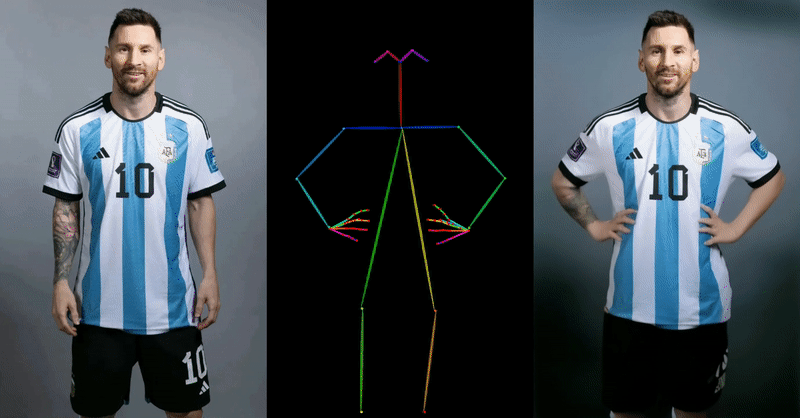
Alibaba’s approach demonstrates superior capabilities in maintaining character details and generating smooth, realistic movements compared to existing methods and technologies. This is a significant advantage in the world of digital animation, where realism and consistency are key.
The team also did some comparisons with similar approaches, such as DreamPose and BDMM, and if you zoom in on the example below – the quality difference is unparalleled:

However, it’s not without its limitations. The method may struggle with highly stable hand movements, leading to distortions. Additionally, since images provide information from only one perspective, animating unseen parts during movement remains a challenge.
Is the model available?
This is extremely high-quality research, and many people will want to get their hands on this model; however – the team that did this paper has not yet published the code (even though they created a GitHub repository).
I recommend following that repository for future updates (as thousands of people already have). In fact, many people are already asking about the model in Issues, but no response from the team yet.
Update (12/5/2023): The team has acknowledged the interest in this model (now at more than 8,000 stars on GitHub) and said the following in an official post,
Thank you all for your incredible support and interest in our project. We’ve received lots of inquiries regarding a demo or the source code. We want to assure you that we are actively working on preparing the demo and code for public release. Although we cannot commit to a specific release date at this very moment, please be certain that the intention to provide access to both the demo and our source code is firm.
Our goal is to not only share the code but also ensure that it is robust and user-friendly, transitioning it from an academic prototype to a more polished version that provides a seamless experience. We appreciate your patience as we take the necessary steps to clean, document, and test the code to meet these standards.
Thank you for your understanding and continuous support.
That said, I think there’s a clear concern about the potential misuse. The ability to create realistic videos of people doing things they never did raises questions about the authenticity of video evidence and the ethical boundaries of AI in media creation.
The technology’s use in industries like pornography and advertising might also be one of the reasons the model is not yet available, as the team might want to rein that aspect in. I can’t even deny it myself, this is a ridiculously good method they found, but it will naturally get abused outside of practical uses.
Technical details
At its core, the method employs a novel framework designed specifically for character animation, using these key components:
- ReferenceNet: This unique network is at the heart of maintaining the intricate details of the character’s appearance from the reference image. ReferenceNet captures spatial details of the reference image and integrates these features into the animation process. It’s built similarly to the denoising UNet structure used in diffusion models but without the temporal layer. The network utilizes spatial-attention mechanisms, which help align and integrate features from the reference image into the video frames, ensuring that the character’s appearance remains consistent throughout the animation.
- Pose Guider: To achieve controllable and realistic character movements, the Pose Guider encodes motion control signals. It uses convolution layers to align the pose image (representing the desired movement) with the noise latent, a foundational component in the diffusion process. This alignment helps guide the character’s movements in the animation, ensuring they align with the desired poses.
- Temporal Layer: For smooth transitions and continuity in the video frames, the temporal layer plays a crucial role. It models the relationships across multiple frames, ensuring the motion looks fluid and natural. This layer is a part of the denoising UNet and operates in the temporal dimension, handling the intricate task of maintaining high-resolution details while simulating a smooth motion process.
The process begins with the Pose Guider encoding a pose sequence, which is then fused with multi-frame noise. This combination goes through the Denoising UNet, which conducts the denoising process essential for video generation. The network’s computational block comprises Spatial-Attention, Cross-Attention, and Temporal-Attention.
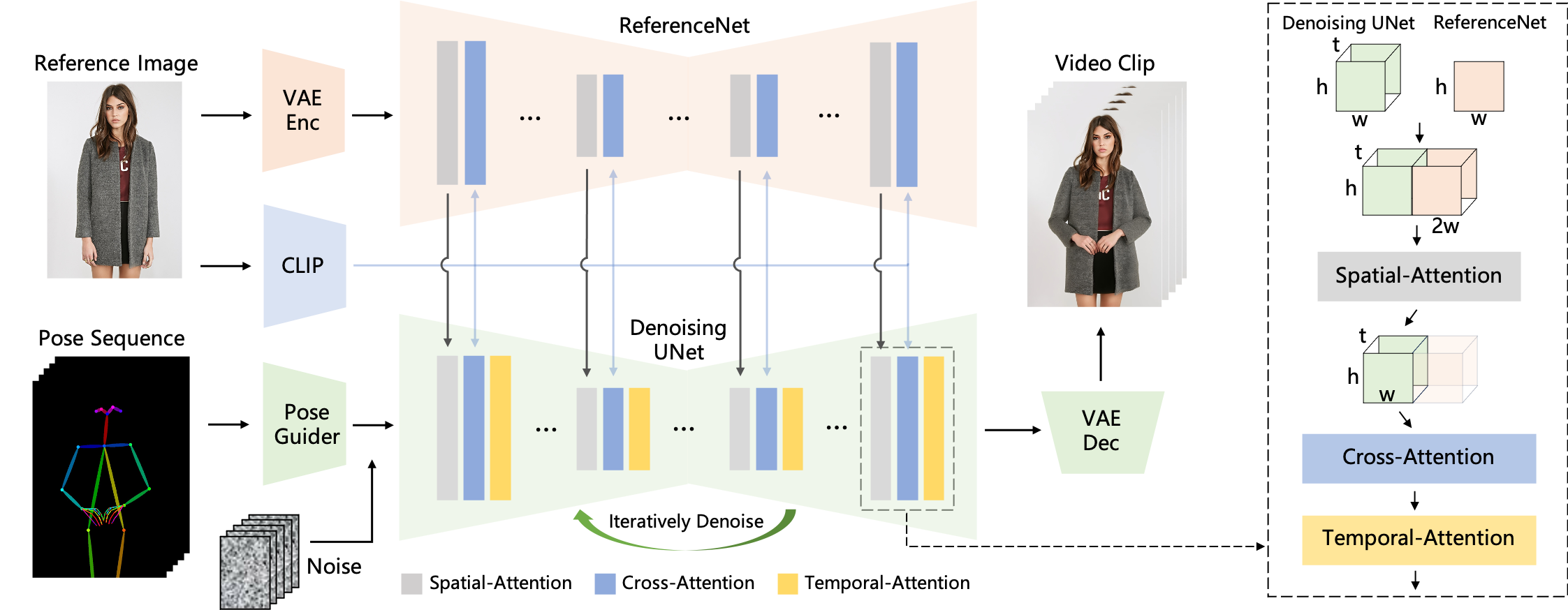
Integrating the reference image involves two aspects: firstly, detailed features extracted through ReferenceNet are used for Spatial-Attention, and secondly, semantic features extracted through the CLIP image encoder for Cross-Attention. This dual approach helps preserve the detailed and semantic integrity of the character’s appearance.
- Training Process and Dataset: The model was trained in two stages. Initially, it was trained using individual video frames, excluding the temporal layer, and focusing on generating high-quality animated images. The second stage introduced the temporal layer, and the model was trained on 24-frame video clips. This staged training approach ensures that the model effectively learns to handle individual frames and the continuity between frames.
The model was trained on an internal dataset of 5,000 character video clips, demonstrating its ability to animate various characters with high-definition and realistic details.