


On the 22nd of August, Stability.ai founder Emad Mostaque announced the release of Stable Diffusion. This AI generative art model has superior capabilities to the likes of DALL·E 2 and is also available as an open-source project. In those weeks since its release, people have abandoned their endeavors and projects to give Stable Diffusion their full attention.
I was already quite excited when OpenAI announced DALL·E 2, and I was also fortunate enough to get early access. But having toyed around with Stable Diffusion for the last couple of days, I can say that DALL·E 2 doesn’t come close to what Stable Diffusion brings to the table.
And the fact that it is open-source also makes it much more accessible. In just two weeks, sites like Lexica have archived over 10 million AI-generated images. I also fully expect that developers will make steady strides to integrate Stable Diffusion with the most popular graphic design tools, such as Figma, Sketch, and others. The ability to generate high-quality art on the go is unprecedented.

The purpose of this article is to list all the interesting and relevant tutorials, resources, and tools to help you quickly get up to speed with Stable Diffusion. I believe over the coming months, we will see a massive influx of projects that specialize in extracting the most potential out of Stable Diffusion. I will do my best to keep this article updated accordingly.
- 👉 Tutorials – this section is focused heavily on topics such as “How to use Stable Diffusion?”.
- 💻 Resources – this section is focused on queries such as “What is Stable Diffusion?”.
- 🚀 Tools – this section is based on tools that let you use Stable Diffusion.
So without further ado – let’s start with the basics.
Resources & Information
One of the first questions many people have about Stable Diffusion is the license this model is published under and whether the generated art is free to use for personal and commercial projects.
The license Stable Diffusion is using is CreativeML Open RAIL-M, and can be read in full over at Hugging Face. In short, “Open Responsible AI Licenses (Open RAIL) are licenses designed to permit free and open access, reuse, and downstream distribution of derivatives of AI artifacts as long as the behavioral-use restrictions always apply (including to derivative works).”.
A more detailed explanation for this license is available on this BigScience page.
What images were used to train the Stable Diffusion model?
AI modeling is the means of creating and training Machine Learning algorithms for a specific purpose. In this case, the purpose of generating images from user prompts.
If you’re curious about which images Stable Diffusion used, Andy Baio and Simon Willison did a thorough analysis of over 12 million images (from a total of 2.3 billion) that were used to train the Stable Diffusion model.
Here are some of the key takeaways:
- The datasets which were used to train Stable Diffusion were the ones put together by LAION.
- Out of the 12 million images they sampled, 47% of the total sample size came from 100 domains, with Pinterest yielding 8.5% of the entire dataset. Other top sources included WordPress.com, Blogspot, Flickr, DeviantArt, and Wikimedia.
- Stable Diffusion doesn’t restrict the use of generating art from people’s names (be it celebrities or otherwise).
It will be interesting to see how the model evolves and whether companies will be willing to contribute their media to help Stable Diffusion grow.
Where to find Stable Diffusion examples & prompts?
One of the ways in which Stable Diffusion differs from the likes of DALL·E is that to get the most out of Stable Diffusion; you have to learn about its modifiers. One modifier, in particular, is called the seed. Whenever you generate an image with Stable Diffusion, that image will be assigned a seed, which can also be understood as the general composition of that image. So, if you enjoyed a particular image and wish to replicate its style (or at least as close as possible), you can use seeds.
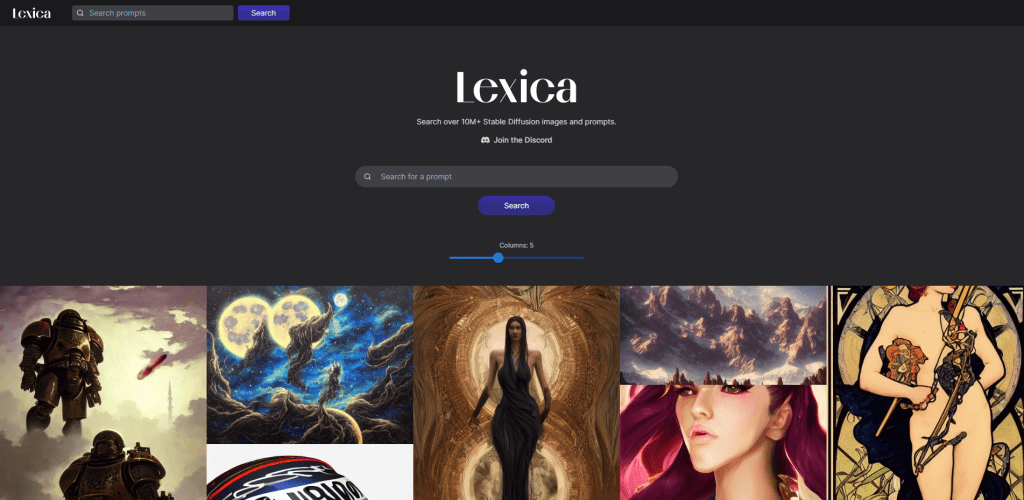
The best platform for finding examples and the prompts used to generate those images is Lexica, which archives over 10 million sample artworks. Each artwork includes its full prompt and the seed number, which you can reuse yourself.
Is there an official Discord server?
Yes!
You can access it by visiting [https://discord.gg/stablediffusion]; important to note that the server no longer supports generating images from the server itself. This feature was available as part of the beta program. If you’d like to use Stable Diffusion from a Discord server – you can look into projects like Yet Another SD Discord Bot, or visit their Discord server to try it out.
Tools & Software
If you’ve seen or been captivated by the art created with Stable Diffusion, you might be wondering whether you can try it out for yourself. And the answer is yes, and there are multiple ways to try Stable Diffusion for free, including doing so from the browser or your machine.
The official way to do so is to use the DreamStudio platform.
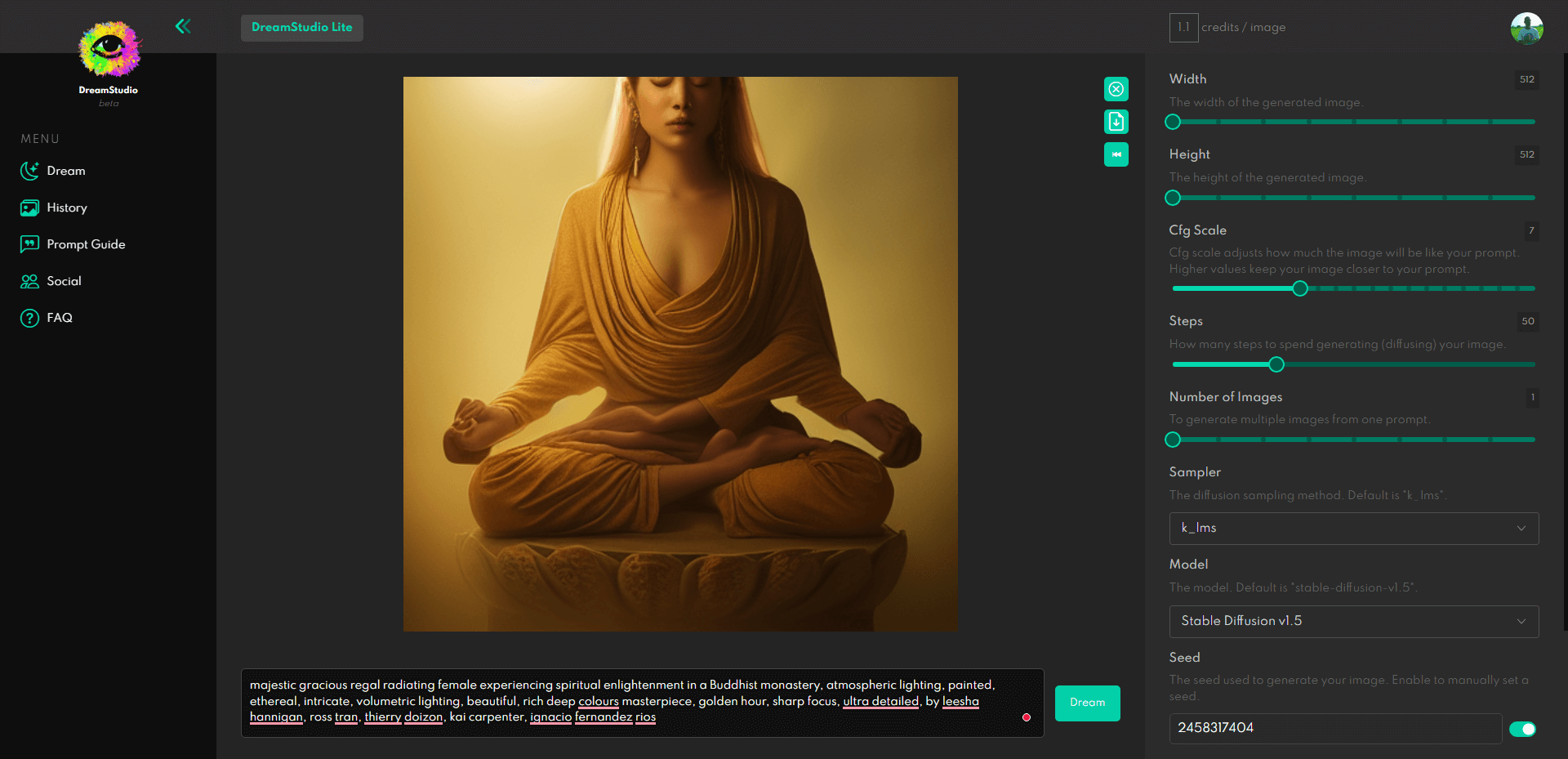
Anyone can register for free, and new accounts get a complimentary 200 free tokens. These tokens are sufficient for 200 generations as long as you don’t increase complexity and don’t change the height and width past the 512×512 default setting. But if you increase the complexity, you’ll probably run out of your tokens quickly.
How to run Stable Diffusion on Windows/Linux?
Currently, the most popular solution for running Stable Diffusion locally is the Stable Diffusion Web UI repo available on GitHub. Based on the Gradio GUI, this is as close as it gets to the DreamStudio interface, and you can wave goodbye to any limitations.
What are the PC requirements for Stable Diffusion?
– 4GB (more is preferred) VRAM GPU (Official support for Nvidia only!)
– AMD users check here
Remember that to use the Web UI repo; you will need to download the model yourself from Hugging Face. Ensure you fully read the Installation guide (Windows) to set it up properly. For Linux, check this guide. And you can also get it up and running on Google Colab – guide here.
Are there any alternatives to running SD on Windows or Linux?
Stable Diffusion UI is gaining popularity (1-click install for Windows and Linux).
How to run Stable Diffusion on a Mac?
Charlie Holtz has released CHARL-E, a 1-click installer for Mac (M1 & M2) users.
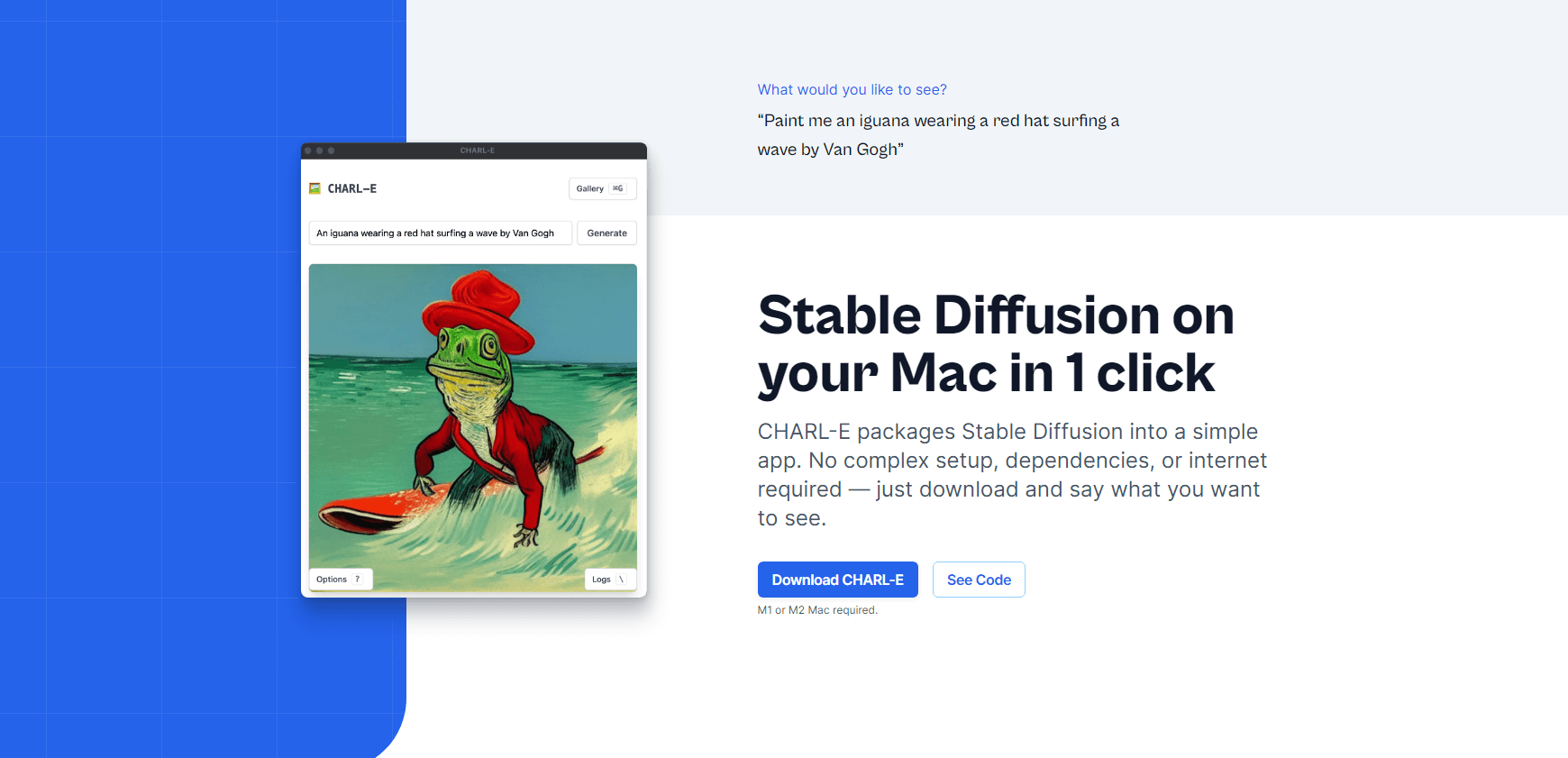
The features:
- Automatically download all the required weights.
- You can set a seed number and DDIM sampling.
- Generated images are saved in a gallery.
There’s also Diffusion Bee to consider as an alternative.
How big is the Stable Diffusion model?
As I mentioned above, you have to download the Stable Diffusion model, and the link can be found here. You will need to create an account on Hugging Face, and, afterward, accept the model’s license terms before you can view and download its files.
⚠️ An important update: The Stable Diffusion model has been upgraded from version 1.4 to version 1.5, and the new version is being maintained by the Runway ML team. The link above has been updated to reflect this change.
One of the questions people have is, “How come the model is only 4GB in size even though it has been made from over 2 billion images?”.
And the best answer to this question comes from a Hacker News user juliendorra ⟶
That’s the interesting part: all the images generated are derived from a less than 4gb model (the trained weights of the neural network).
So in a way, hundreds of billions of possible images are all stored in the model (each a vector in multidimensional latent space) and turned into pixels on demand (drived by the language model that knows how to turn words into a vector in this space)
As it’s deterministic (given the exact same request parameters, random seed included, you get the exact same image) it’s a form of compression (or at least encoding decoding) too: I could send you the parameters for 1 million images that you would be able to recreate on your side, just as a relatively small text file.
Tutorials & Guides
The following section is dedicated entirely to tutorials and guides to help you extract the most juice from your Stable Diffusion prompts. As I said, I will do my best to keep this updated as more guides become available and a better understanding of the model is gained.
Stable Diffusion Prompt Builder
There are additional style guides below, but as far as building prompts visually – the promptoMANIA tool is probably the best there is.
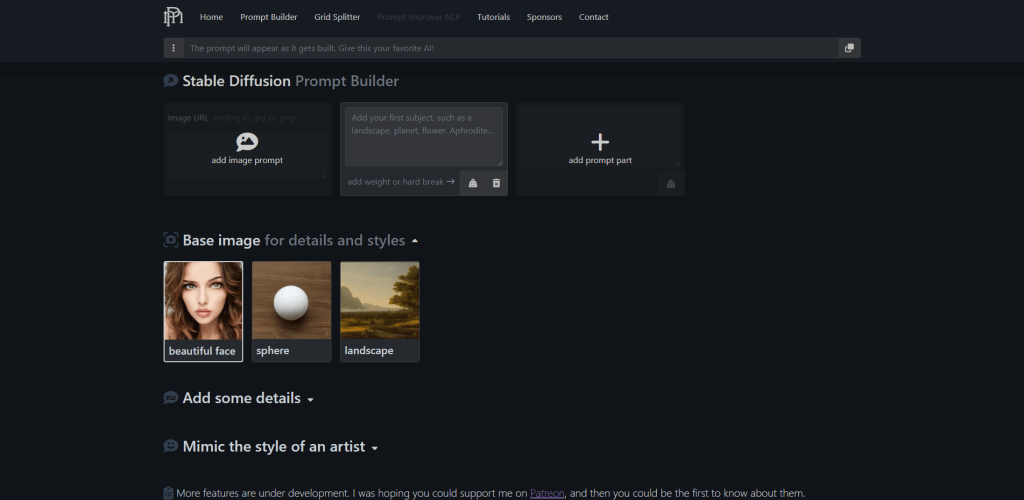
You can start by adding the description of the image that you’re trying to create, and then you can scroll down to start adding details and mimic the styles of various artists. There are hundreds of options to choose from, each with a visual preview.
Once you’re finished building your string, you can copy it and then paste it into whatever tool you use to generate Stable Diffusion images.
1,500 Artist Examples

This website lets you preview various artistic styles by listing more than 1,500 unique artists. You can also click on the artist’s name form and search for individual artists. All the images that are rendered are examples of what that artist’s filter would look like in Stable Diffusion.
VectorArt
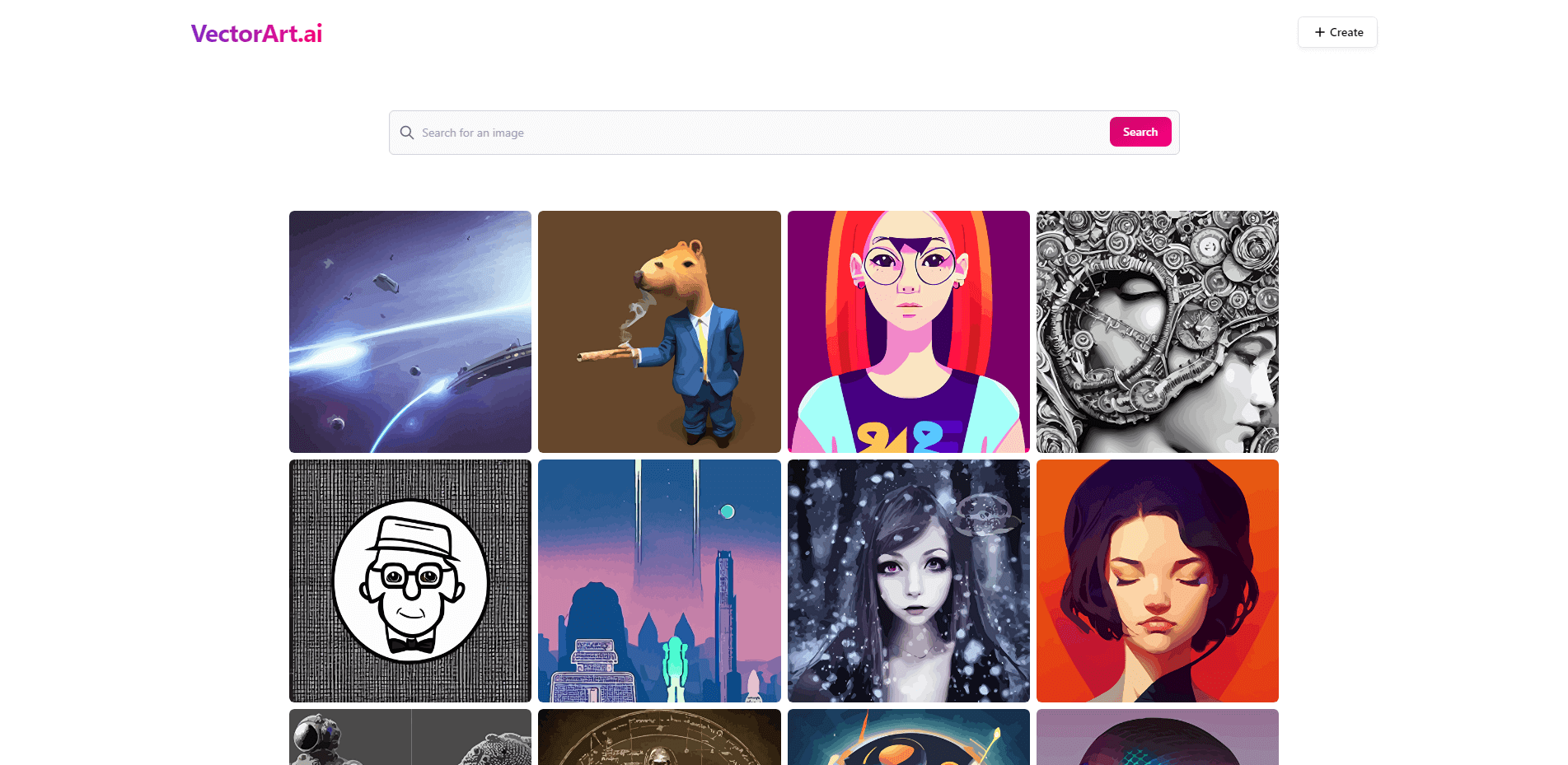
The VectorArt.ai website is very similar to that of Lexica. The only difference is that VectorArt focuses on listing vector-based graphics generated with Stable Diffusion. Much like Lexica, this website also includes the prompt that was used to generate a specific image.
―
And here are other various resources related to styles and prompts:
- Ultimate Beginner’s Guide – Arman Chaudhry published a compact Google Docs presentation on the essentials of SD. This guide covers all of the modifiers that SD supports but also recommends the best practices for width/height settings and common mistakes to avoid.
- Akashic Records – If you’re looking to do a deep dive (or need references for research) – the SD Akashic Records repository has an astounding amount of resources for you to study. You’ll find everything from keyword usage, to prompt optimization, to style guides. There are also mentions of several tools, outside of those already mentioned in this article.
- Art Styles & Mediums – Check out this Google Docs file for up to 100+ different styles and mediums to use for your SD image generation. The document is based on a single prompt, and the said prompt has been generated in hundreds of different styles so that you can replicate the same style in your prompts.
- Visual & Artist Styles – Check out this modifiers.json file on GitHub for additional styles and artist recommendations. It’s over 200 different modifiers you can apply to your prompts.