


If you haven’t yet read my original article, “The shady world of Brave selling copyrighted data for AI training“, I recommend that you do so (it includes a reply from Brave, too) because you will need the context to understand why I am publishing an update. I also want to apologize for wasting people’s time and using Wikipedia as an example because clearly, Wikipedia has a lenient license that Brave can get around by giving “attribution”.
I also want to apologize for assuming that Brave gives you rights to copyrighted data; in the original article, I did not explain that when an AI model is being trained, you don’t attribute any data because if you did – this is what your ChatGPT experience would look like for every single query:

Is it legal to do what Brave does? There isn’t a clear answer to this, but at the very least there are serious ethical considerations, particularly acknowledging the fact that Brave thinks they have the right to sell people’s content because they are a search engine, their words, not mine. And to top it off, you cannot block their crawler, even if you did find that Brave was explicitly extracting data from your website that you would rather not have extracted. Brave operates under the notion that if Google is allowed to do this, they are allowed to do it as well, again, their words and not mine.
So, let’s get some facts straight, and here is what I will show in this update:
- The Brave Search API is specifically designed to give you more content (data) than you would from their regular search engine. A single request to their API can return up to 1,000 words at a time and possibly more, depending on the query you send.
- The Brave Search API does not respect the site’s licensing, and Brave is under the assumption that 1) because they are a search engine and 2) because they attribute the URI of data – this puts them in the clear to scrape and resell data word-for-word.
Let’s start with the first fact.
Brave’s search API is designed to give you more data
The first query I am sending is the same one I used in the original article “brave search”, after copying the entire page from top to bottom and counting its words, the total is at roughly 500 words. These are basic excerpts that you would expect a search engine to show.
Now let’s see what happens when I send the same query, “brave search” through their Data for AI API:
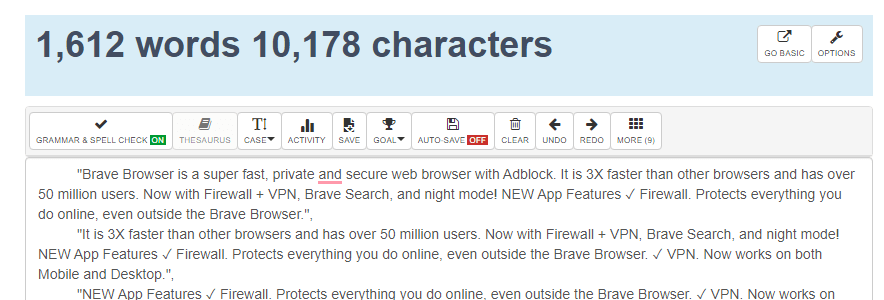
You can also view the full JSON response here:
A simple example of licensed content

One thing I was curious about with the “Extra Snippets” feature is whether or not Brave can extract data below the fold, which I can now confirm that they can.
The URL in question:
New York Times Tech Staff to Walk Out in Growing Union Fight
And here is what Brave has to say about it:
"extra_snippets": [
"Tech workers play an important role at large media companies like the Times, which have had to adapt their business models to serve online audiences and advertisers. An escalation in the dispute there could inspire similar activism by nonunion tech staff elsewhere. ... “It’s disappointing that the union is more focused on attention-seeking tactics than in having constructive dialogue with the company over the critical issue of who is eligible for the proposed bargaining unit -- a standard part of the NLRB election process,” Times spokesperson Danielle Rhoades Ha said in an email Tuesday.",
"The company is “confident that we are following the letter of the law,” denies any wrongdoing, and is “committed to working with the union in good faith to determine the appropriate unit and schedule an election,” she said. The guild, which represents 1,300 editorial and business employees at the Times, publicly unveiled a campaign in April to organize the tech workers and says 70% have signed a petition pledging to vote for the union. The union has filed several still-pending National Labor Relations Board complaints in recent weeks over what it alleges has been an illegal anti-union campaign by management, including interrogating workers about their activism.",
"“It’s disappointing that the union is more focused on attention-seeking tactics than in having constructive dialogue with the company over the critical issue of who is eligible for the proposed bargaining unit -- a standard part of the NLRB election process,” Times spokesperson Danielle Rhoades Ha said in an email Tuesday. The company is “confident that we are following the letter of the law,” denies any wrongdoing, and is “committed to working with the union in good faith to determine the appropriate unit and schedule an election,” she said.",
"After trying unsuccessfully to reach a deal with the company for an electronic vote overseen by a third party, the guild petitioned the U.S. labor board to hold an election among the roughly 600 tech workers it seeks to represent. Management is asking the agency to restrict the vote to software engineers only, which would shrink the potential bargaining unit by more than a third, according to a union spokesperson. On Monday, Rhoades Ha said the Times was disappointed that the guild had gone public with the discussions over who should be in the bargaining unit, and that there were “questions and critical issues to address” given that “a tech-focused unit of this size and scope is unprecedented” to date."
]The full JSON can be seen here:
Please note that I don’t have the resources to sit all day and send thousands of queries and index and parse the data based on licenses, but know that the Brave Search API provides “Unlimited queries per month” for the priciest premium plans, and I don’t see a world in which this cannot be abused.
It’s my understanding that perhaps Brave thinks this is a “fair use” situation, but I’m not a lawyer, and I am not able to comment on it; I can only show the facts.