


Stack Overflow has announced changes to its data-dump process, primarily focusing on where the data will be accessed. This move is part of a broader strategy to encourage “socially responsible AI” practices among companies that use the platform’s data.
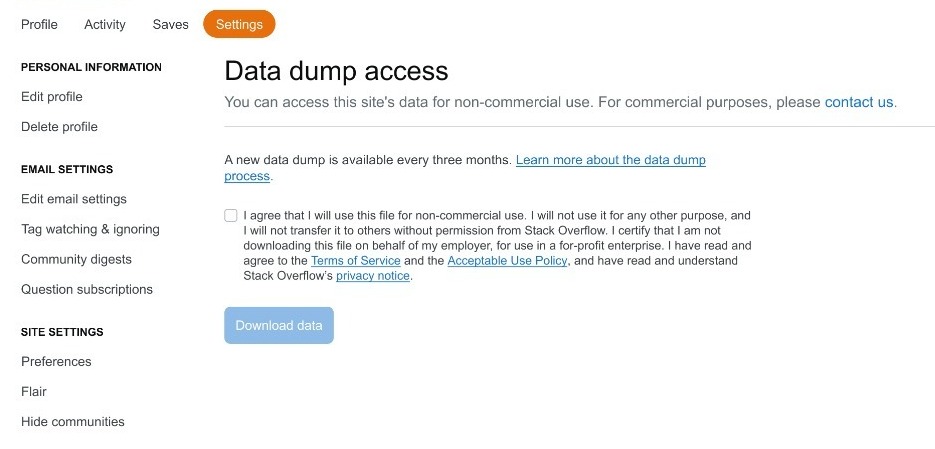
Previously, users could access Stack Overflow’s data dumps via Archive.org. Moving forward, these dumps will be available directly from user profiles on Stack Exchange sites.
The data dumps contain anonymized versions of questions, answers, comments, and user information, allowing for extensive research and analysis. This change aims to improve the speed and efficiency of accessing the data, which has been a pain point for many users. “While Archive.org has been a great partner to us, both internally and externally, people have encountered challenges with uploading and downloading the dumps with any reasonable speed,” explains the announcement.
Commercial pressure and social responsibility
One of the key reasons behind this change is to exert commercial pressure on large language model (LLM) manufacturers. Stack Overflow advocates for these companies to join their “socially responsible AI” initiative, ensuring they give back to the communities whose data they consume. “We are attempting to protect the long-term viability of the Stack Exchange network and to ensure that it is a comprehensive and well-attributed resource for generations to come,” the announcement states.
This initiative stems from the knowledge that many companies have been scraping Stack Overflow data to train their AI models, often without proper attribution. By centralizing the data dumps on their own platform, Stack Overflow aims to encourage these companies to adhere to the CC BY-SA 4.0 license, which mandates proper attribution to the community members who contribute content.
Simplified and efficient access
According to Stack Overflow, the new data dump process will be more user-friendly. Users will be able to generate a URL for the data dump directly from their account settings on the Stack Exchange site. This instant format is expected to streamline access and make the process quicker and more efficient.
The change also aims to foster innovation within the community. With easier access to the data, Stack Overflow is curious to see what new tools and analyses community members will develop. “With the heightened ease of receiving a dump, we’re curious to see what community members will build with this information,” they note.
In addition to changing the data dump access location, Stack Overflow is enhancing its measures against data scraping. The platform plans to add more checks for bots and harden its infrastructure to prevent unauthorized data scraping. This move is in response to longstanding community requests for better protection against such activities.
While the new process is set to be implemented in mid-August, Stack Overflow acknowledges that this timeline means they will miss the previous commitment date for the July data dump. They are, however, open to accommodating urgent and critical needs for updated data on a case-by-case basis until the new system is live.
Stack Overflow says this change should have little practical impact on everyday users accessing the data dumps. The primary goal is to ensure that companies using the data for commercial purposes do so responsibly and contribute back to the community.
For those with unusual needs for the full data dump file, Stack Overflow is developing a process to accommodate these requests in future updates. For now, users with critical needs are encouraged to reach out via the contact form for assistance.