One of the most annoying things about the “modern” web is paywalls. More and more publishers are choosing to lock their content behind premium subscriptions or email signup forms. And in this article, I am going to explain why paywalls exist, and how to bypass them.
I want to make it absolutely clear that I do not condone the act of avoiding paying for premium content. Publishers should be rewarded for their work, and I respect that. But it’s not only big publishers like New York Times that are causing problems.
A lot of blogs on Medium are doing borderline shady tactics to force people into sharing their email addresses. And I will do my best to explain how. Another issue is when sites block access from the entire EU region because of GDPR regulations. More on that soon.
If you want to skip the technical part, click here to jump straight to the tools section.
What is a Paywall?
In the most basic terms, a paywall is used to protect website content that is intended to be paid for. The cost can be either monetary – subscription – or an email address to help grow a newsletter.
The reasoning behind using a paywall is quite simple: ad-blockers are hindering publisher revenue streams. And this has been happening for more than a decade now.
Google reported in 2017 that, “[…] more than 600 million devices use ad-blockers”. It’s only fair to assume that this number has grown exponentially since then.

If you’re a big publisher and you depend on advertising revenue, it makes sense to transition over to a subscription model. However, my angle on this topic is related to search engines.
Specifically, how publishers let search engines like Google crawl and index their content but do not let the searcher read it.
How do search engines access paywalled content?
So, let me illustrate what happened and why I wrote this article in the first place. When doing research for my open-source analytics article, I wanted to know the impact that ad-blockers have on analytics reports.
In particular, how ad-blockers affect the reporting of tools like Google Analytics.
My search query for this was: “ad blockers analytics tracking”.
And here is the search result from Google:
The first result is from Towards Data Science and it is a featured snippet. These snippets are Google’s way of giving you a quick answer to a specific question. And, they are stickied to the top of the search result page as to imply authority.
Nevertheless, the answer is quite straightforward, but I wanted to know more. So, I clicked on the article’s link. And this is the page I was greeted with:
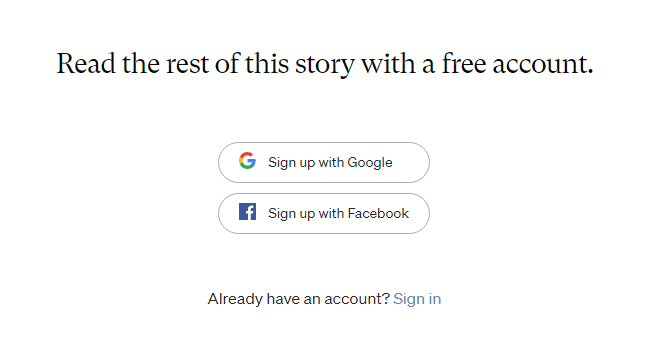
My first thought? This is annoying as hell. My second thought? How did Google see this article and promote it in search results?
Of course, I'm not trying to be ignorant. I know that Medium limits how many articles you can read a month. Though, keeping track of how many you have read is not feasible. Especially, considering that you can use custom domain names for your Medium blogs.
In this case, Towards Data Science is publishing its content on Medium. And Medium offers creators a way to earn money for publishing with their platform. It’s a business relationship more than a personal issue of trust. But here is my gripe with it.
In order for this content to flourish, it depends heavily on search engine traffic.
So, the Google Crawler is given a free pass to both see the entire page’s content, but also to index it in search results. And as we saw above, those search results can be promoted to authoritative status. Which, honestly, doesn’t make any sense.
Google’s stance on paywalled content

Google has created an official guideline for how to structure paywalled content using schema markup. You can see the official docs here.
In summary:
- Google does not allow content cloaking.
- Paywalled content has to be marked up to the exact section that is hidden behind a paywall.
How actively Google enforces these rules is unknown.
I did my due diligence on Towards Data Science, and here is the code they’re using on that specific page:
mainEntityOfPage: https://towardsdatascience.com/how-much-data-is-missing-from-your-google-analytics-dashboard-20506b26e6d
isAccessibleForFree: False
cssSelector: .meteredContentAs we can see here, isAccessibleForFree is to False, and the CSS selector is set to .meteredContent. It tells us that Medium is following Google guidelines on how to structure paywalled content.
What is the “.meteredContent” selector?
This selector is used to tell search engines like Google that there is a limit to how many free articles a user can read. In the case of Medium, it is 3 free articles per month.
Admittedly, while on a hunt to find real wrongdoing on Medium’s part, I came back empty-handed. I think, logically, it doesn’t make sense that Google can see all the articles, but real readers only get to read 3 articles before they are forced to sign up. Google seems to be more than happy to allow this kind of behavior, and there is not much else I can say.
Google has openly stated that it is more interested in the quality of content as opposed to caring about its accessibility. The company initially published guidelines on telling publishers to allow at least 3 free articles for first-time visitors. This is true for what we saw with Medium. But, in recent years, Google has shifted to structured markup. Read more about this in the "How Search algorithms work" article from Google itself.
Blocked in EU because of GDPR
In some cases, you might come across websites that block access entirely. This is largely relevant for US-based publishers who block access for EU readers. And the simple reason for this is the GDPR – privacy regulations from Europe.

While the image above implies that the website at hand “cares” about EU visitors, it’s clearly not the case in practical terms. The reason publishers do this is because of complicated advertising techniques which gather data about users. And, rather than limiting what data is tracked for a specific region, some choose to block access entirely.
How to bypass paywalls
Alright, let’s look past all the drama and reasoning behind paywalls. Instead, let’s explore some of the tools you can use to quickly bypass a paywall.
12ft Ladder
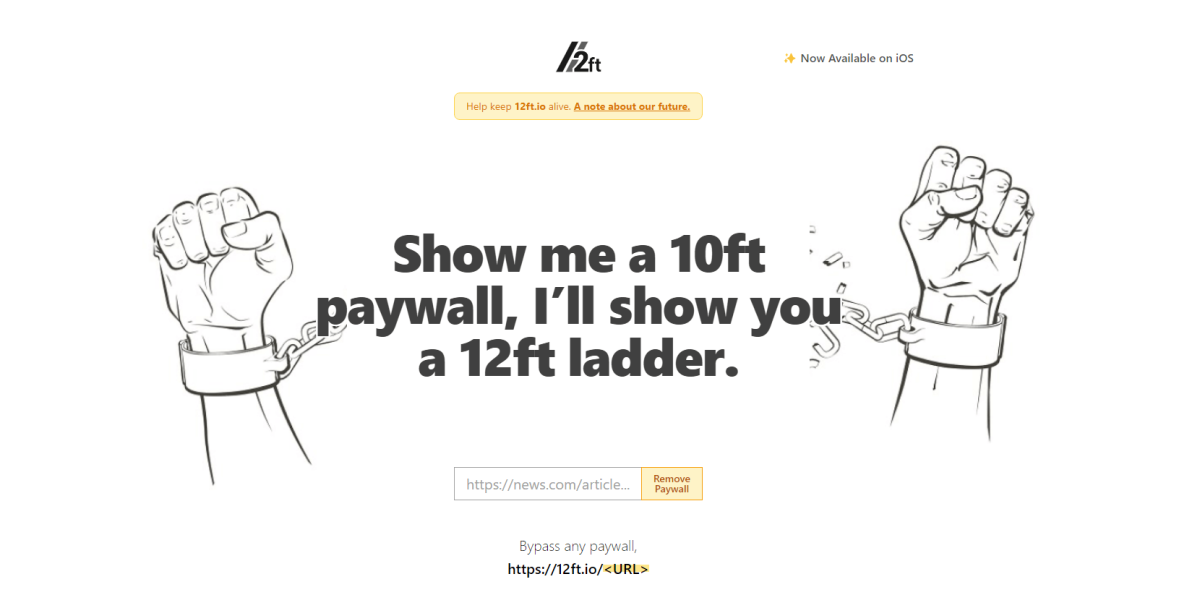
The quickest way to get past a paywall is to use the 12ft Ladder website. All you have to do is enter the URL that links to a paywall, and 12ft will do the rest.
https://12ft.io/[link to the paywalled website]As for how it works, it’s quite simple. News sites, publishers, and other content providers use paywalls but allow Google Crawler to see their pages. In this context, 12ft simply uses the Google Cache feature to show you the full page.
To my knowledge, 12ft does not support bypassing The New York Times.
Bypass Paywalls

The Bypass Paywalls browser extension is an open-source project hosted on GitHub. In order to use this specific extension, you have to install it yourself. As it is not available for download on either Google Chrome marketplace or Mozilla’s.
The extension itself is available for Chrome, Firefox, and Edge browsers. Last but not least, the project has over 20,000 stars on GitHub. So, it is both time-tested and also reliable. The full list of sites that you can bypass with this extension is on the project page itself.
Archive
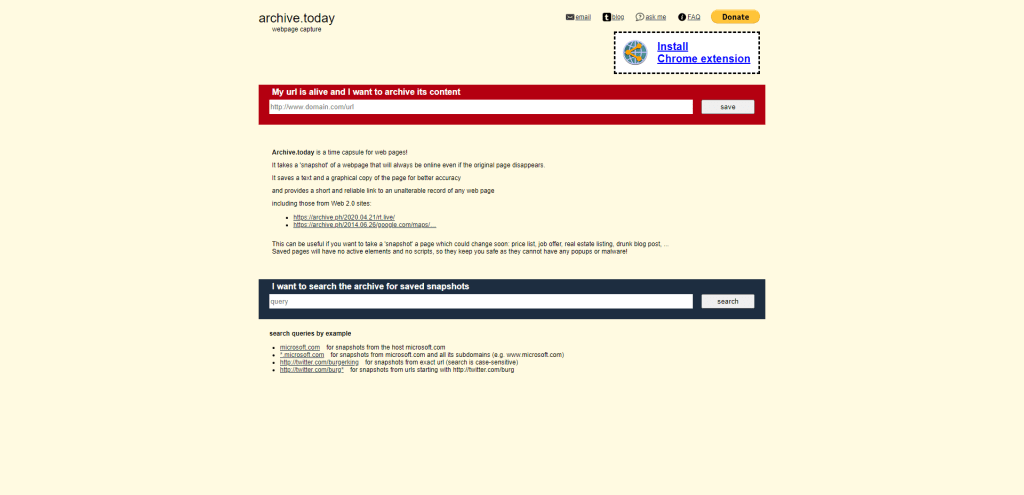
The Archive Today project works similarly to many other paywall bypassing tools. It archives the pages as if the page was browsed by a search engine, and gives you back a readable version of the page you’re trying to view.
This method is often seen to be used on sites like Hacker News where people submit stories behind paywalled content. From what I can tell, it works fine with sites like NY Times, Financial Times, The Wall Street Journal, and numerous others.
The best way to use this website is first to use the second form on the homepage to look up if a page hasn’t already been archived. If the article is older than a few hours, then in most cases – there will be a non-paywalled copy already available. If not, then simply make a copy yourself using the first form.
Incognito Mode
In some cases, a website will store cookie data to monitor how many free articles you have read. Once you reach the limit, you will be paywalled. And, one of the easier ways to circumvent that is through Incognito Mode. Also known as a private mode.
You can access Incognito on any modern browser by going to Settings and selecting a new Private Window. This will simply give you a “blank slate” with no cookie history, meaning that you can go ahead and access content hidden behind a cookie paywall.
Incoggo

The folks behind Incoggo are planning on entering the ad-blocker market. But, for the time being, they provide free Mac-based software to skip paywalls. Again, this software is only available to OSX users, though a Windows version should surface soon.
Looking at their latest blog news, it seems that the project is in active development. This is good news because it means that the software works when needed. As for which publications and sites Incoggo can skip – check their official website.
Disable JavaScript

One last thing you can do to bypass paywalls is to disable JavaScript in your browser and then refresh the paywalled page. Although it is technically possible to do through browser settings, the best way to do this is to use an extension like uBlock Origin (an ad-blocker) that lets you disable JavaScript for each website individually.
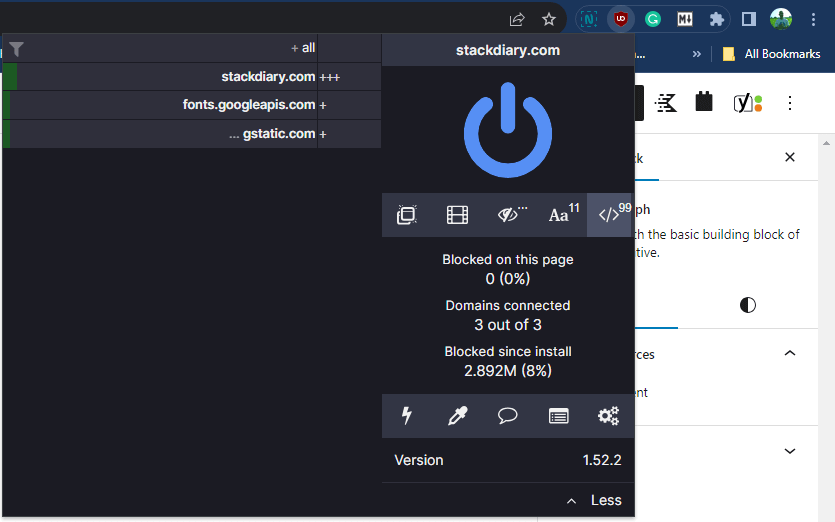
From the uBlock interface, you can click on the button </> to disable JavaScript, and then reload the page. Afterward, you can enable it back. Keep in mind that doing this will sometimes not render images on the site, particularly for those sites that specifically load all images using JavaScript.
Is it ethical to bypass paywalls?
I think we all operate at varying levels of moral compass. There are a lot of arguments to be had on both sides. And, as I mentioned at the start of the article, I do think that publishers should be able to charge subscription fees for premium content.
My only problem is when this process becomes extortion. In other words, why give privileges to search engines like Google and then lock out all other users?
It’s not uncommon to be reading a genuine free article, which links to publishers that have added paywalls to their content.
Is it really worth paying $50 a year to read just one article? The same goes for articles that were once free, but are still being linked to despite the paywall.
Whatever the case, I hope this guide gave you at least some useful takeaways.