The rapidly evolving landscape of AI has led to groundbreaking advancements in various industries, particularly in the realm of music and audio tools.
In this article, we will explore how AI-powered platforms such as Soundraw and Replica Studios are revolutionizing how content creators produce and integrate audio elements into their projects.
By providing unique, customizable, and royalty-free music and AI voice actors, these innovative platforms are transforming the creative process and granting users unprecedented control over their work.
LALAL – extract vocals and more from video & audio.
Powered by artificial intelligence, LALAL.AI has established itself as the world’s leading vocal remover and music source separation service, catering to streamers, journalists, transcribers, musicians, and many other creative professionals.
LALAL’s team of specialists in AI, machine learning, mathematical optimization, and digital signal processing have developed in-house neural networks like Rocknet, Cassiopeia, and Phoenix, each iteration more advanced than the previous. With each development, the platform sets a new benchmark in the industry, now offering an unparalleled 10-stem splitter that even includes wind and string instruments.
In addition to LALAL’s stem-splitting capabilities, they have also introduced Voice Cleaner, a noise cancellation solution that effortlessly removes background music, mic rumble, and vocal plosives, delivering crystal-clear audio.
This has made the platform indispensable for professionals who require high-quality audio for various applications.
Pricing: Free Starter, Plus pack €30/€50, or Lite pack €15. Up to 300+50 min, 2GB file upload, and various input/output formats available. Plus and Lite pack offer fast processing queue, batch upload, and stem download. Individual use only.
Adobe Podcast – optimize and edit your audio.
Adobe has once again demonstrated its commitment to innovation with the introduction of Adobe Podcast. Designed for storytellers who require a seamless and user-friendly audio recording and editing platform, Adobe Podcast harnesses the power of artificial intelligence to deliver a cutting-edge solution for audio enthusiasts and professionals alike.
At the core of Adobe Podcast’s revolutionary approach to audio editing is the use of Adobe Premiere Pro’s speech-to-text technology. This transformative feature allows users to edit audio using a transcript, making the editing process more efficient and intuitive than traditional waveform editing.
Remote recording capabilities make Adobe Podcast stand out as a versatile tool for modern content creators. By simply sharing a link, users can record high-quality audio with others, while the platform automatically syncs the recordings in the cloud for seamless collaboration.
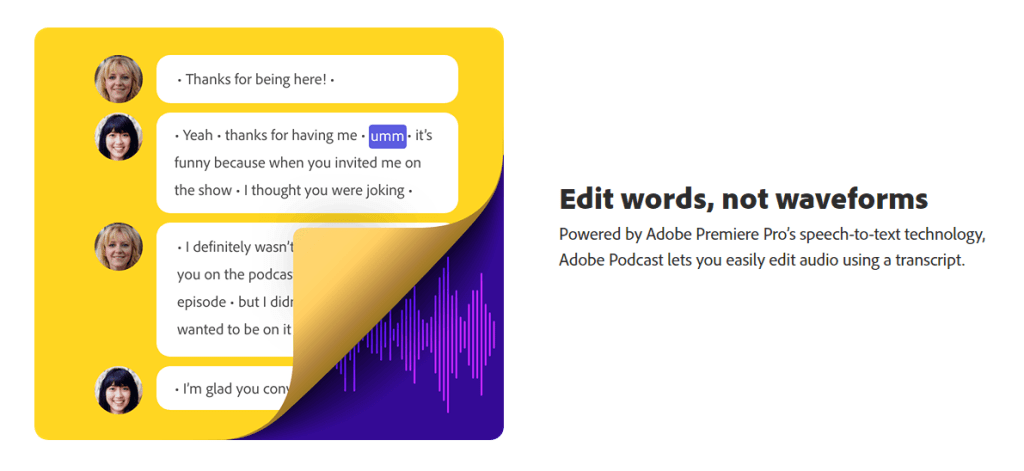
Adobe Podcast’s AI-powered audio enhancement tools, such as Enhance Speech and Mic Check, further elevate the platform’s offerings.
Enhance Speech increases audio clarity by eliminating background noise and refining voice frequencies, simulating a professional studio experience. Meanwhile, Mic Check assesses and provides guidance for optimizing microphone setups, ensuring consistently clear audio output.
Pricing: The platform is in early access at the moment, so it is free to try.
AssemblyAI – API for developers.
AssemblyAI’s Core Transcription and Audio Intelligence models enable businesses to transcribe and analyze audio using AI models built on the latest research. These models offer async transcription, real-time transcription, speaker labels, international languages, summarization, sentiment analysis, PII redaction, and entity detection, among other capabilities.
Designed with developers in mind, AssemblyAI offers comprehensive resources such as in-depth tutorials, detailed changelogs, and extensive documentation to ensure a smooth experience at every step of the development process. From product overviews and video tutorials to industry updates, AssemblyAI is committed to providing developers with the tools they need to build exciting new products.
Conformer-1
In a world where speech recognition and audio analysis are becoming increasingly crucial for businesses, AssemblyAI has emerged as a game-changer with its state-of-the-art speech recognition model, Conformer-1.

Conformer-1 is a new and advanced speech recognition model. It has been trained on a massive amount of audio data totaling 650,000 hours. This model boasts exceptional performance, nearing that of human-level capabilities. Additionally, it demonstrates strong adaptability and can handle diverse data sets.
Pricing: Pay-As-You-Go pricing for Core Transcription ($0.00025/sec) and Audio Intelligence ($0.000583/sec). Try both APIs for free.
Musico – compose music with AI.
Musico is an AI-driven software engine that is transforming the music industry by generating a limitless supply of original, adaptive, and copyright-free music. Harnessing the power of artificial intelligence, Musico caters to a wide range of users, including professional musicians, media developers, and artists, enabling them to create and manipulate sound in innovative ways.
At the heart of Musico lies its revolutionary AI composition. By combining traditional and modern machine learning algorithms, Musico is capable of producing endless streams of music in a variety of styles.
This generative approach offers creators new opportunities to produce and apply sound that adapts to its context in real-time.
From semi-assisted to fully automatic composition, Musico’s engines cater to both music professionals and non-musicians alike.
Musico’s innovative features include:
- AI-Assisted Composition: Musico’s engines generate infinite melodies, beats, and harmonies, blending autonomy and responsiveness to the creator’s input. This AI-powered toolbox enables users to craft everything from musical sketches to full songs.
- Augmented Performance: Apps like Impro allow musicians and performers to generate music in real time, controlling Musico with intuitive gestures.
- Guided Sound Generation: The engines can be mapped and react in real time to various control signals, opening up endless possibilities of interaction.
- Auto-Scoring for Digital Storytelling and Media: Musico is exploring the relationship between music and narrative to develop a next-generation soundtrack plugin for storytellers, game developers, and cross-media creators.
Musico’s core engines are designed to work seamlessly with a variety of input strategies, opening new possibilities for any product or service involving music.
Cleanvoice – clean up your podcasts and audio files.
Cleanvoice is an innovative artificial intelligence solution that streamlines the podcast editing process by automatically removing filler sounds, stuttering, and mouth sounds from audio recordings.
Key features of Cleanvoice include:
- Multilingual Filler Sound Remover – detects and eliminates filler sounds such as “um’s” and “ah’s” in multiple languages, including German and French. The algorithm can also work with various accents from countries like Australia and Ireland.
- Mouth Sounds & Stuttering Removal – common recording artifacts like clicking, lip-smacking, and stuttering are detected and removed by Cleanvoice, resulting in a cleaner and more professional sound.
- Dead Air Remover – by identifying and shortening long silences, Cleanvoice helps to create a more engaging podcast experience for listeners.
- Timeline Export – for users who prefer manual editing, Cleanvoice offers timeline export functionality. This feature allows you to import Cleanvoice’s suggested edits into your editing software, giving you more control and saving time in the editing process.
Utilizing Cleanvoice is super easy:
- Upload your audio file(s)
- The AI performs the cleaning
- Download or Export the Results
In addition to its core features, Cleanvoice offers several other tools to enhance your podcast, such as background noise removal, podcast transcription, and podcast mixing services. These features help to ensure that your audio content is polished and professional, making it more appealing to your target audience.
Pricing: Free trial with 30 minutes credit. Subscription options: 10hrs audio/mo for 10€, 30hrs audio/mo for 25€, 100hrs audio/mo for 80€. Pay as you go options: 5hrs audio for 10€, 30hrs audio for 40€. Unused credits roll over (max 3x).
Emergent Drums – the name gives it away.
Emergent Drums is an innovative music plugin that utilizes artificial intelligence to generate an endless array of unique drum samples, all royalty-free. With a one-time purchase of $149 (currently on sale from $249), music producers gain access to this revolutionary tool, which is already making waves in the industry.
Key features of Emergent Drums include:
- Endless Drum Sounds – the plugin can generate an unlimited number of drum sounds, allowing users to create without limitations. Every sound is unique and created from scratch, ensuring true originality.
- Customizable Kits – users can build their own kits with 16 royalty-free sounds, customizing each sound with fine-tuned effects.
- Multiple Views – emergent Drums offers different views, including Compact View, to suit your workflow preferences.
- Intuitive Interface – the plugin’s small pad provides an array of sample generation and artistic control options. Users can easily navigate through previously generated samples, trim each sample to their liking, and fine-tune various parameters to achieve the perfect sound.
Emergent Drums’ AI model is trained on a vast database of drum and percussion samples, allowing it to generate a nearly infinite number of unique drum samples.
The plugin supports VST2, VST3, and AU (64-bit) formats on Windows 7 or later and macOS 10.11 or later. It only requires internet access to generate new samples, and the generated samples can be used offline.
Pricing: With a 30-day money-back guarantee, users can try Emergent Drums risk-free. Though currently lacking a trial version, the developers are working to introduce one in the future.
Replica – AI voice acting.

Replica Studios has taken the voice-over industry by storm with its innovative AI voice actors. This cutting-edge platform allows users to generate realistic and emotionally charged voice performances for games, films, and the rapidly growing metaverse.
Replica Studios offers an ever-expanding library of AI voice actors, with over 40 voices and new additions every week. The platform has been praised for its ease of use in generating voice lines for gaming, animation, and various creative projects. Replica’s technology makes voice-over production cost-effective and accessible to indie creators and those with limited budgets.
The AI voices are created through a rigorous training process that involves real voice actors spending hours teaching the AI to mimic their speech patterns, pronunciation, and emotional range. This results in AI-generated performances that are impressively similar to human voices.
Aside from the impressive library of AI voices, Replica Studios offers a range of features such as script creation, prototyping, audio export, direct emotions, and speech controls. Collaboration tools are also in the pipeline, promising a comprehensive platform that caters to diverse creative projects.
Pricing: Replica offers a free trial, with no credit card required. The Casual Plan costs $36 for 4 hours of speech generation credit, while the Enterprise Plan is available for unlimited speech generation and additional features. The Enterprise Plan is suitable for audiobook and film studios, as well as SaaS products.
SoundRaw – Royalty-free music using AI.
Soundraw is an AI-powered music generator that allows creators to produce tailor-made, royalty-free music at their fingertips. The platform offers users an innovative solution to overcome the limitations of traditional music licensing, granting them the freedom to create unique soundtracks for their work.
Soundraw’s AI algorithm allows users to generate an unlimited number of songs by selecting the desired mood, genre, and length. The platform’s customization features enable creators to fine-tune songs by adjusting elements like intros and choruses, ensuring the soundtrack perfectly complements their projects.
One of the key advantages of Soundraw is the elimination of copyright concerns. As the music generated by the platform is royalty-free, creators can safely use it in their projects without fearing copyright strikes on platforms like YouTube.

Soundraw’s straightforward pricing plans cater to a wide range of users. The free plan allows users to generate unlimited songs and bookmark them for future reference. The paid Personal plan, priced at $16.99 per month (billed annually), provides added benefits such as personal and commercial use rights, downloads of up to 50 songs per day, and usage in various media formats including corporate videos, web ads, podcasts, games, and apps.
Summary
In conclusion, the rise of AI music and audio tools is unlocking new creative horizons for content creators. These cutting-edge platforms are not only eliminating common challenges associated with traditional music licensing and voice acting but are also fostering greater innovation in the industry.
As AI technology continues to evolve, we can expect even more groundbreaking developments that will further reshape the way we approach music and audio production, pushing the boundaries of what is possible and redefining the future of creative expression.